Writing My Own Language (Part 2)
25 Jul 2024
7 minute read
Contents
I decided to write my own programming language to solve this year’s Advent of Code. This includes an interpreter, syntax highlighting, and a language server. In the first part, we looked at how the interpreter works. In this part, we’ll take a look at how I implemented syntax highlighting.
Approach §
How to implement syntax highlighting depends on the editor that you use. I use Neovim, where Tree-sitter is usually used for it.
Tree-sitter is a fast and robust parser generator tool. It can be used to (relatively) easily create a parser for a language. The generated parser can be used to walk and inspect the syntax tree. It also supports advanced pattern matching with queries.
I implemented the syntax highlighting using the following steps:
- Create a parser for the AOC language by defining its grammar.
- Define which nodes in the syntax tree represent keywords, variables, values, etc. This is done by defining highlighting queries using the previously mentioned query language.
- Update the Neovim configuration to use a custom Tree-sitter grammar and highlighting queries.
Defining The Grammar §
Tree-sitter rules are defined in the grammar.js file. Each rule has a name
and can be defined as a string constant, regular expression, or a combination
of other rules by using the provided functions. Rules whose names are prefixed
with '_' are hidden in the syntax tree. This is useful for defining rules
like _expression, which wraps just one node. For those interested, a more
in-depth explanation of how to write rules is available in
the official documentation.
Basic Structure §
All the possible rules are collected in the _rules rule, which is defined as:
_rules: ($) =>
choice(
$._expression,
$.assignment,
$.for_loop,
$.while_loop,
$.continue,
$.break,
$.return,
);
The function choice matches one of the possible rules. This allows me to
reference any rule later in the grammar. As you can see, I also grouped all
expressions1 into an _expression rule.
The root node of the syntax tree is the source_file node, which is defined like this:
source_file: ($) => repeat(seq($._rules, terminator)),
where terminator is
const terminator = choice("\n", "\0");
This basically means that the source_file is a sequence of many rules and each
rule ends with a new line or EOF.
The mandatory new line character between the rules is handled here and not in
the _rules node, because I sometimes need to reference the _rules node
and don’t need it to be terminated with a new line character.
Take for loops as an example:
for (initial; condition; after) { ... }
Here, initial and after are both _rules nodes but don’t require
ending with a new line character.
With the basic grammar structure laid down, we can take a look at some more interesting rules.
Prefix & Infix §
For prefix and infix expressions, I obviously had to deal with precedence. It
turns out that Tree-sitter makes this easy for us. First, we define a PREC
enum, which is just copied over from the interpreter code.
const PREC = {
lowest: 0,
assign: 1,
or: 2,
and: 3,
equals: 4,
less_greater: 5,
sum: 6,
product: 7,
prefix: 8,
call_index: 9,
};
Then we can use the prec.left function to define the left precedence of a rule.
We use prec.left instead of prec because the interpreter is also
left-associative and we want to keep that behavior.
A prefix expression is easy since there are only two prefix operators and both have the same precedence.
prefix_expression: ($) =>
prec.left(
PREC.prefix,
seq(field("operator", choice("!", "-")), field("right", $._expression)),
),
Function field creates a named field in the node, that can later be used
for more exact querying.
There are many infix expressions, and they have different precedences.
I used JS’s map function to make it simple:
infix_expression: ($) => {
const operators = [
["+", PREC.sum],
["*", PREC.product],
// ...
];
return choice(
...operators.map(([operator, precedence]) =>
prec.left(
precedence,
seq(
field("left", $._expression),
field("operator", operator),
field("right", $._expression),
),
),
),
);
},
Blocks §
Remember how the source_file rule also handles the required new line character?
There is one more place we have to handle the new line character: block expressions.
A block expression contains whatever is between the { and } in function
definitions, for loops, if statements, etc.
However, the block expression is different from source_file in one way:
the last statement doesn’t have to end with a new line. For instance, we can write:
if (true) { 10 }
I had to handle an empty block separately; otherwise, the grammar was ambiguous
and Tree-sitter couldn’t generate the parser from it. In the end, the
block definition looks like this:
block: ($) =>
choice(
// empty block
seq("{", "}"),
// at least one rule
seq(
"{",
repeat(seq($._rules, terminator)),
seq($._rules, optional(terminator)),
"}",
),
),
I used a similar trick for arrays, dictionaries, function definitions,
and function calls, where the last expression can be followed by a , or not.
// Both definitions are valid
a = [1, 2]
b = [1, 2,]
Strings §
Correctly parsing strings turns out to be more challenging than it looks. This is due to the fact that our strings also support escaping, which means that this is a valid string:
"foo \"bar\""
Therefore, we can’t just write a regular expression that captures everything
between two ".
AOC lang’s strings are very similar to Go’s strings, so I took inspiration from tree-sitter-go.
To define a string rule, we have to use token.immediate.
The official documentation tells us the following about it:
Usually, whitespace (and any other extras, such as comments) is optional before each token. This function means that the token will only match if there is no whitespace.
With this newly learned function, we can define a string as a sequence of
alternating basic contents and escape sequences:
string: ($) =>
seq(
'"',
repeat(choice($._string_basic_content, $.escape_sequence)),
token.immediate('"'),
),
The basic content of a string is anything that is not ", \n, or \.
Or, in the language of regular expressions, the basic content is [^"\n\\]+.
In the grammar, I defined it as:
_string_basic_content: () => token.immediate(prec(1, /[^"\n\\]+/)),
We use token.immediate to make sure that new lines and comments are handled
by string rules and not ignored. We also give it a precedence of 1 to ensure
that the grammar is not ambiguous and that something is parsed as an escape
sequence only if it’s not basic content.
While on the topic of escape sequences, let’s define them! They are easier to
define than basic content, since an escape sequence is just \ followed
by a single character:
escape_sequence: () => token.immediate(/\\./),
Highlighting Queries §
After the grammar was complete, I could add it to my neovim config2 and start working on highlighting queries.
Most of the highlighting queries were pretty straightforward. I looked at the
nvim-treesitter highlighting documentation
and wrote queries for the capture groups that I wanted to implement. For instance,
here is an example of how I implemented various @keyword capture sub-groups:
(continue) @keyword
(break) @keyword
"fn" @keyword.function
"use" @keyword.import
["for" "while"] @keyword.repeat
"return" @keyword.return
["if" "else"] @keyword.conditional
However, there were some things that I had to change in the grammar definition to allow for correct querying.
First, I learned that adding fields on nodes allows for more precise querying.
For instance, I initially didn’t have a function field on the function_call
node. The initial query for the @function.call group therefore looked like this:
(function_call
(identifier) @function.call)
But this highlighted all the identifiers in the function call as if they were
a @function.call. In this example:
foo(a, b, c)
a, b, c are all identifiers and get captured as the @function.call
group. But the correct query would capture only foo as @function.call.
After adding the function field to the function_call node, the query was
easy to write and worked as intended:
(function_call
function: (identifier) @function.call)
The second change I had to implement in my grammar definition was to define two different nodes for the two different ways of indexing a dictionary. If you remember from the first part, there are two ways to index a dictionary:
foo["bar"]
foo.bar
If a user indexes an object with dot notation, I want to highlight the index
as a @property. Having a separate dot_index node for the dot index made this easy:
(dot_index
index: (identifier) @property)
With the highlighting queries complete, the code now looks like this:
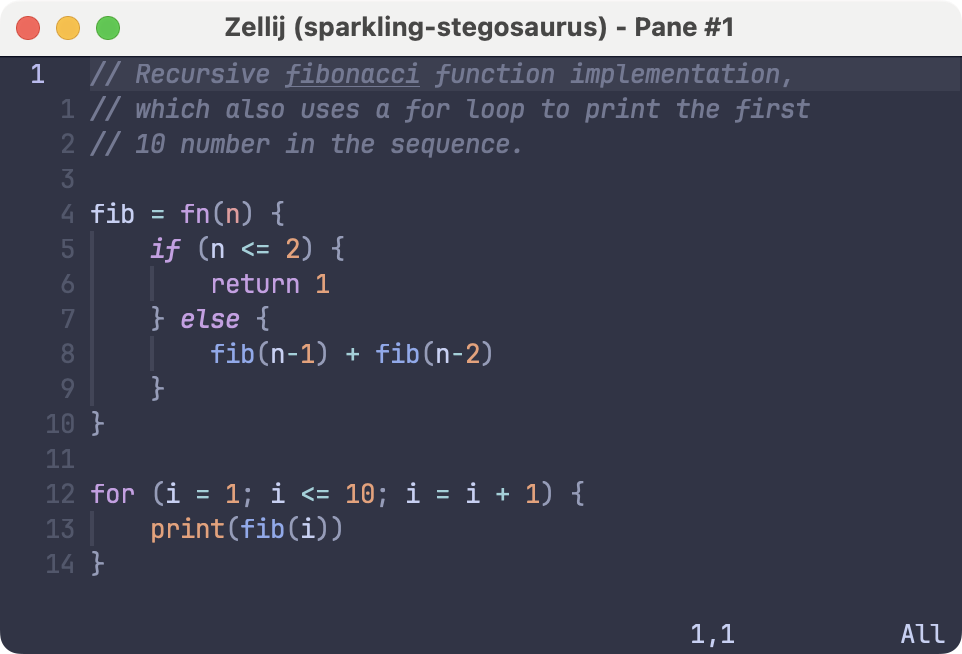
Conclusion §
I was positively surprised by how easy it is to get started with tree-sitter. There is a ton of documentation and examples on how to write a parser. And getting started with writing queries is even easier! Overall I enjoyed using tree-sitter and hope to be able to use it in the future as well.
-
In the first part, I defined an expression to be anything that “returns a value.” For instance, identifiers, infix operations, and array literals are all expressions. ↩︎
-
If you want to add AOC lang highlighting to your neovim config, see the project’s README. ↩︎